
Gemma3-4B GRPO微调教程
话不多说,直接开始!
本文使用的测试环境为单张 A100,显存 80GB,可根据需求切换不同参数量的模型,实测4B 24G显存 is enough! 使用的框架为 Unsloth  Unsloth 是一个极其强调资源节省的框架,把所有的资源节省做到了极致,具体来讲Unsloth能够将 Llama-3、Mistral、Phi-4 和 Gemma 等大型语言模型的微调速度提升 2 倍,内存占用减少 70%,并且准确率没有任何下降! 官方文档非常全面,详细指导了如何训练自己的定制模型。其中涵盖了安装和更新 Unsloth、创建数据集、运行和部署模型等基本要素。 Unsloth 让大家在本地或在 Google Colab 和 Kaggle 等平台上训练像 Llama 3 这样的模型变得极其简单。Unsloth简化了整个训练工作流程,包括模型加载、量化、训练、评估、运行、保存、导出,以及与 Ollama、llama.cpp 和 vLLM 等推理引擎的集成。 Unsloth定期与 Hugging Face、Google 和 Meta 的团队合作,以修复 LLM 训练和模型中的错误。因此,当使用 Unsloth 进行训练或使用模型时,可以期待获得最准确的结果。 Unsloth 具有高度可定制性,允许更改聊天模板或数据集格式等内容。Unsloth还为视觉、文本转语音 (TTS)、BERT、强化学习 (RL) 等提供了预构建的脚本!此外,Unsloth支持所有训练方法和所有基于 Transformer 的模型。
Unsloth 是一个极其强调资源节省的框架,把所有的资源节省做到了极致,具体来讲Unsloth能够将 Llama-3、Mistral、Phi-4 和 Gemma 等大型语言模型的微调速度提升 2 倍,内存占用减少 70%,并且准确率没有任何下降! 官方文档非常全面,详细指导了如何训练自己的定制模型。其中涵盖了安装和更新 Unsloth、创建数据集、运行和部署模型等基本要素。 Unsloth 让大家在本地或在 Google Colab 和 Kaggle 等平台上训练像 Llama 3 这样的模型变得极其简单。Unsloth简化了整个训练工作流程,包括模型加载、量化、训练、评估、运行、保存、导出,以及与 Ollama、llama.cpp 和 vLLM 等推理引擎的集成。 Unsloth定期与 Hugging Face、Google 和 Meta 的团队合作,以修复 LLM 训练和模型中的错误。因此,当使用 Unsloth 进行训练或使用模型时,可以期待获得最准确的结果。 Unsloth 具有高度可定制性,允许更改聊天模板或数据集格式等内容。Unsloth还为视觉、文本转语音 (TTS)、BERT、强化学习 (RL) 等提供了预构建的脚本!此外,Unsloth支持所有训练方法和所有基于 Transformer 的模型。
unsloth使Gemma3(4B)微调速度提高2倍,VRAM使用减少70%,并且比所有使用Flash Attention 2的环境支持长8倍的上下文长度。使用unsloth,Gemma3–4B模型可以舒适地在仅24GB VRAM的环境中运行。 unsloth为Gemma3提供了Dynamic 2.0量化方法,在5-shot MMLU和KL散度基准测试中提供最佳性能。这意味着可以运行和微调量化后的Gemma3 LLM,同时保持最小的精度损失。unsloth还上传了支持原生长上下文的Gemma3版本。
教程概览
本教程将指导您完成 Gemma3-4B 模型的 GRPO(Group Relative Policy Optimization)微调,这是一种先进的强化学习技术,专门用于提升大语言模型在特定任务上的表现。
什么是GRPO?
GRPO(Group Relative Policy Optimization)是一种强化学习优化技术,通过设计多个奖励函数来评估模型输出的不同方面,从而指导模型学习期望的行为模式。在数学推理任务中,GRPO可以帮助模型:
- 学会按照特定格式输出答案
- 提高推理过程的逻辑性
- 增强答案的准确性
- 改善输出的结构化程度
本教程的学习内容
- 环境设置: 安装Unsloth和相关依赖
- 模型加载: 加载Gemma3-4B预训练模型
- LoRA配置: 设置高效的参数微调
- 数据处理: 处理GSM8K数学推理数据集
- 格式设计: 定义结构化的输出格式
- 奖励函数: 设计多维度评估体系
- GRPO训练: 执行强化学习微调
- 效果验证: 测试微调后的模型
- 模型保存: 保存训练结果
- 可视化监控: 使用SwanLab跟踪训练过程
步骤1: 安装必要的依赖包
安装软件包
# pip install --no-deps unsloth vllm==0.8.5.post1步骤2: 加载预训练模型和分词器
准备模型,设置参数
# 导入必要的库
from unsloth import FastModel # Unsloth的快速模型加载接口
import torch # PyTorch深度学习框架
# 设置最大序列长度
# 这个参数决定了模型能处理的最大文本长度(以token为单位)
max_seq_length = 1024
# 加载预训练模型和分词器
# 这里我们加载Gemma3-4B的指令微调版本
model, tokenizer = FastModel.from_pretrained(
model_name = "google/gemma-3-4b-it", # 模型路径
max_seq_length = max_seq_length, # 最大序列长度
load_in_4bit = False, # 不使用4位量化,保持精度
load_in_8bit = False, # 不使用8位量化,保持精度
full_finetuning = False, # 使用LoRA微调,不进行全参数微调
)步骤3: 配置LoRA(Low-Rank Adaptation)
# 配置LoRA(Low-Rank Adaptation)参数
# 将基础模型转换为PEFT(Parameter Efficient Fine-Tuning)模型
model = FastModel.get_peft_model(
model,
# 层级配置:决定哪些层参与微调
finetune_vision_layers = False, # 关闭视觉层微调(仅文本任务)
finetune_language_layers = True, # 开启语言层微调(必须)
finetune_attention_modules = True, # 开启注意力模块微调(对GRPO很重要)
finetune_mlp_modules = True, # 开启MLP模块微调(建议保持开启)
# LoRA核心参数
r = 8, # LoRA的秩:控制适应层大小,值越大精度越高但可能过拟合
lora_alpha = 8, # LoRA的缩放因子:建议设置为r的值或略大
lora_dropout = 0, # LoRA的dropout率:防止过拟合,这里设为0
bias = "none", # 偏置项设置:不训练偏置项
random_state = 3407, # 随机种子:确保结果可复现
)步骤4: 加载和探索GSM8K数据集
设置CoT思考模版【让模型具备思考能力的必经之路】
# 加载GSM8K数据集
from datasets import load_dataset
# 从本地路径加载GSM8K数据集的训练集
# GSM8K是一个包含小学数学推理问题的数据集
dataset = load_dataset("openai/gsm8k", "main", split = "train")
# 查看数据集基本信息
print(f"数据集大小: {len(dataset)} 条记录")
print(f"数据集特征: {dataset.features}")
dataset# 定义函数提取最终答案
# GSM8K数据集中,最终答案位于####符号之后
def extract_hash_answer(text):
"""
从GSM8K答案中提取最终数值答案
Args:
text (str): 包含推理过程和最终答案的完整文本
Returns:
str or None: 提取的最终答案,如果没有####标记则返回None
"""
if "####" not in text:
return None
# 分割文本,取####后面的部分并去除空格
return text.split("####")[1].strip()
# 测试提取函数
final_answer = extract_hash_answer(dataset[0]["answer"])
print(f"提取的最终答案: {final_answer}")
# 验证提取结果
final_answer步骤5: 设计输出格式和系统提示词
# 定义输出格式的标记符号
# 这些标记帮助我们识别和评估模型输出的不同部分
reasoning_start = "<start_working_out>" # 推理过程开始标记
reasoning_end = "<end_working_out>" # 推理过程结束标记
solution_start = "<SOLUTION>" # 最终答案开始标记
solution_end = "</SOLUTION>" # 最终答案结束标记
# 创建系统提示词
# 这个提示词指导模型按照我们期望的格式输出答案
system_prompt = f"""You are given a problem.
Think about the problem and provide your working out.
Place it between {reasoning_start} and {reasoning_end}.
Then, provide your solution between {solution_start}{solution_end}"""
print("系统提示词内容:")
print(system_prompt)
print("\n这个提示词告诉模型:")
print("1. 需要思考问题")
print("2. 将推理过程放在指定标记之间")
print("3. 将最终答案放在SOLUTION标记之间")
system_prompt加载数据集【这里使用一个数学推理的数据集】
步骤6: 转换数据集格式
# 转换数据集格式
# 将原始数据转换为对话格式,便于模型训练
dataset = dataset.map(lambda x: {
# 构建对话prompt,包含系统提示和用户问题
"prompt" : [
{"role": "system", "content": system_prompt}, # 系统消息:指导输出格式
{"role": "user", "content": x["question"]}, # 用户消息:具体的数学问题
],
# 提取标准答案,用于后续的奖励计算
"answer": extract_hash_answer(x["answer"]),
})
print("转换后的数据格式示例:")
print("1. prompt包含系统提示和用户问题")
print("2. answer是提取的数值答案")
print(f"3. 数据集大小保持不变: {len(dataset)} 条")
# 查看转换后的第一个样本
dataset[0]步骤7: 设计奖励函数系统
奖励函数部分
GRPO的核心是通过奖励函数来指导模型学习。我们将设计4个奖励函数来评估模型输出的不同方面:
7.1 首先定义正则表达式来匹配期望的格式
# 导入正则表达式库
import re
# 定义正则表达式来匹配期望的输出格式
# 这个正则表达式确保模型输出包含所有必需的标记并按正确顺序排列
match_format = re.compile(
rf"^[\s]{{0,}}" # 开头可以有任意数量的空白字符
rf"{reasoning_start}.+?{reasoning_end}.*?" # 推理过程部分(非贪婪匹配)
rf"{solution_start}(.+?){solution_end}" # 解决方案部分(捕获组获取答案)
rf"[\s]{{0,}}$", # 结尾可以有任意数量的空白字符
flags = re.MULTILINE | re.DOTALL # 多行模式,.匹配换行符
)
print("正则表达式说明:")
print("1. 匹配从<start_working_out>到<end_working_out>的推理过程")
print("2. 匹配从<SOLUTION>到</SOLUTION>的最终答案")
print("3. 捕获SOLUTION标记内的内容作为答案")
print("4. 允许前后有空白字符")7.2 奖励函数1: 精确格式匹配
def match_format_exactly(completions, **kwargs):
"""
奖励函数1: 检查输出是否严格遵循指定格式
Args:
completions: 模型生成的完成文本列表
**kwargs: 其他参数(未使用)
Returns:
list: 每个完成文本的奖励分数列表
"""
scores = []
for completion in completions:
score = 0
response = completion[0]["content"]
# 如果输出完全匹配期望格式,给予高分奖励
if match_format.search(response) is not None:
score += 3.0
scores.append(score)
return scores
print("奖励函数1说明:")
print("- 检查输出是否包含完整的推理过程和解决方案格式")
print("- 格式正确: +3.0分")
print("- 格式不正确: 0分")7.3 奖励函数2: 近似格式匹配
def match_format_approximately(completions, **kwargs):
"""
奖励函数2: 检查格式标记的出现次数
这个函数更宽松,检查各个格式标记是否恰好出现1次。
如果某个标记出现1次,获得奖励;如果出现0次或多次,会被惩罚。
Args:
completions: 模型生成的完成文本列表
**kwargs: 其他参数(未使用)
Returns:
list: 每个完成文本的奖励分数列表
"""
scores = []
for completion in completions:
score = 0
response = completion[0]["content"]
# 检查每个标记的出现次数,理想情况下每个标记应该恰好出现1次
score += 0.5 if response.count(reasoning_start) == 1 else -0.5
score += 0.5 if response.count(reasoning_end) == 1 else -0.5
score += 0.5 if response.count(solution_start) == 1 else -0.5
score += 0.5 if response.count(solution_end) == 1 else -0.5
scores.append(score)
return scores
print("奖励函数2说明:")
print("- 检查每个格式标记的出现次数")
print("- 每个标记出现1次: +0.5分")
print("- 每个标记出现0次或多次: -0.5分")
print("- 总分范围: -2.0 到 +2.0")7.4 奖励函数3: 答案正确性检查
def check_answer(prompts, completions, answer, **kwargs):
"""
奖励函数3: 检查答案的正确性
这个函数实现了多层次的答案评估机制,从严格匹配到近似匹配。
Args:
prompts: 输入提示列表
completions: 模型生成的完成文本列表
answer: 标准答案列表
**kwargs: 其他参数
Returns:
list: 每个完成文本的奖励分数列表
"""
question = prompts[0][-1]["content"]
responses = [completion[0]["content"] for completion in completions]
# 从模型输出中提取答案
extracted_responses = [
guess.group(1)
if (guess := match_format.search(r)) is not None else None \
for r in responses
]
scores = []
for guess, true_answer in zip(extracted_responses, answer):
score = 0
# 如果无法提取答案,得分为0
if guess is None:
scores.append(0)
continue
# 完全匹配:最高奖励
if guess == true_answer:
score += 3.0
# 去除空格后匹配:高奖励
elif guess.strip() == true_answer.strip():
score += 1.5
else:
# 数值接近性检查:对于数值答案,允许一定误差
try:
ratio = float(guess) / float(true_answer)
if ratio >= 0.9 and ratio <= 1.1: # 10%误差内
score += 0.5
elif ratio >= 0.8 and ratio <= 1.2: # 20%误差内
score += 0.25
else:
score -= 1.0 # 错误答案惩罚
except:
score -= 0.5 # 无法转换为数值的惩罚
scores.append(score)
return scores
print("奖励函数3说明:")
print("- 完全匹配: +3.0分")
print("- 去空格匹配: +1.5分")
print("- 10%误差内: +0.5分")
print("- 20%误差内: +0.25分")
print("- 错误答案: -1.0分")
print("- 无法解析: -0.5分")7.5 奖励函数4: 数值提取检查
# 定义用于提取数字的正则表达式
# 这个正则表达式专门用于从SOLUTION标记中提取数值
match_numbers = re.compile(
rf"{solution_start}.*?([\d\.]{{1,}})", # 匹配SOLUTION标记内的数字(包括小数)
flags = re.MULTILINE | re.DOTALL # 多行模式
)
# 测试数字提取功能
test_solution = "<SOLUTION> 0.34 </SOLUTION>"
extracted_numbers = match_numbers.findall(test_solution)
print(f"测试文本: {test_solution}")
print(f"提取的数字: {extracted_numbers}")
print("✓ 数字提取正则表达式工作正常" if extracted_numbers else "✗ 数字提取失败")
extracted_numbersdef check_numbers(prompts, completions, answer, **kwargs):
"""
奖励函数4: 检查数值提取能力
这个函数专门检查模型是否能在SOLUTION标记内输出有效的数值,
并与标准答案进行精确数值比较。
Args:
prompts: 输入提示列表
completions: 模型生成的完成文本列表
answer: 标准答案列表
**kwargs: 其他参数
Returns:
list: 每个完成文本的奖励分数列表
"""
question = prompts[0][-1]["content"]
responses = [completion[0]["content"] for completion in completions]
# 使用数字提取正则表达式从响应中提取数值
extracted_responses = [
guess.group(1)
if (guess := match_numbers.search(r)) is not None else None \
for r in responses
]
scores = []
# 打印调试信息(训练时会显示)
print('*'*20, f"Question:\n{question}",
f"\nAnswer:\n{answer[0]}",
f"\nResponse:\n{responses[0]}",
f"\nExtracted:\n{extracted_responses[0]}")
for guess, true_answer in zip(extracted_responses, answer):
# 如果无法提取数字,得分为0
if guess is None:
scores.append(0)
continue
# 尝试将提取的答案和标准答案转换为数值进行比较
try:
true_answer_num = float(true_answer.strip())
guess_num = float(guess.strip())
# 数值完全匹配时给予奖励,否则为0
scores.append(1.5 if guess_num == true_answer_num else 0.0)
except:
# 转换失败时得分为0
scores.append(0)
continue
return scores
print("奖励函数4说明:")
print("- 专门检查SOLUTION标记内的数值提取")
print("- 数值完全匹配: +1.5分")
print("- 无法提取数值或不匹配: 0分")
print("- 用于确保模型输出包含有效数字")步骤8: 配置GRPO训练参数
GRPO部分
# 设置提示词的最大长度
max_prompt_length = 256
# 导入GRPO相关的配置和训练器
from trl import GRPOConfig, GRPOTrainer
# 创建GRPO训练配置
training_args = GRPOConfig(
# 优化器参数
learning_rate = 5e-6, # 学习率:GRPO通常使用较小的学习率
adam_beta1 = 0.9, # Adam优化器的beta1参数
adam_beta2 = 0.99, # Adam优化器的beta2参数
weight_decay = 0.1, # 权重衰减,防止过拟合
optim = "adamw_torch_fused", # 使用融合的AdamW优化器,更高效
# 学习率调度
warmup_ratio = 0.1, # 学习率预热比例
lr_scheduler_type = "cosine", # 余弦学习率调度
# 训练批次设置
per_device_train_batch_size = 1, # 每个设备的批次大小
gradient_accumulation_steps = 1, # 梯度累积步数(可以增加到4获得更平滑的训练)
num_generations = 4, # 每个提示生成的候选数量(显存不足时可减少)
# 序列长度控制
max_prompt_length = max_prompt_length, # 提示的最大长度
max_completion_length = max_seq_length - max_prompt_length, # 完成文本的最大长度
# 训练控制
max_steps = 50, # 最大训练步数(演示用,实际训练建议更多)
save_steps = 50, # 保存模型的步数间隔
max_grad_norm = 0.1, # 梯度裁剪阈值
# 日志和监控
logging_steps = 1, # 日志记录间隔
report_to = "swanlab", # 这里改成swanlab
output_dir = "outputs", # 输出目录
)
print("GRPO训练配置已设置完成!")
print(f"- 最大训练步数: {training_args.max_steps}")
print(f"- 每步生成候选数: {training_args.num_generations}")
print(f"- 学习率: {training_args.learning_rate}")
print(f"- 使用SwanLab进行可视化监控")步骤9: 执行GRPO训练
# 创建GRPO训练器
# 训练器整合了模型、奖励函数、训练参数和数据集
trainer = GRPOTrainer(
model = model, # 要训练的模型
processing_class = tokenizer, # 分词器(用于文本处理)
# 奖励函数列表:这些函数将评估模型输出质量
reward_funcs = [
match_format_exactly, # 奖励函数1:严格格式匹配
match_format_approximately, # 奖励函数2:近似格式匹配
check_answer, # 奖励函数3:答案正确性
check_numbers, # 奖励函数4:数值提取
],
args = training_args, # 训练配置参数
train_dataset = dataset, # 训练数据集
)
print("GRPO训练器创建完成!")
print("包含的奖励函数:")
print("1. match_format_exactly - 检查完整格式")
print("2. match_format_approximately - 检查标记使用")
print("3. check_answer - 检查答案正确性")
print("4. check_numbers - 检查数值提取")
print("\n开始训练...")
# 开始GRPO训练
# 注意:训练过程中会显示大量调试信息,包括问题、答案和模型输出
trainer.train()步骤10: 测试训练后的模型
训练完毕后调用模型
# 构建测试消息
# 使用训练时相同的系统提示词,但提出一个新问题
messages = [
{"role": "system", "content": system_prompt}, # 使用相同的格式指导
{"role": "user", "content": "What is the sqrt of 101?"}, # 新的数学问题
]
# 将消息转换为模型输入格式
text = tokenizer.apply_chat_template(
messages,
add_generation_prompt = True, # 添加生成提示,告诉模型开始回答
tokenize = False, # 先不分词,保持文本格式
)
print("测试问题: What is the sqrt of 101?")
print("期望输出格式:")
print("- 包含 <start_working_out> ... <end_working_out> 的推理过程")
print("- 包含 <SOLUTION> ... </SOLUTION> 的最终答案")
print("\n模型输出:")
# 导入文本流输出器,用于实时显示生成过程
from transformers import TextStreamer
# 生成回答
_ = model.generate(
**tokenizer(text, return_tensors = "pt").to("cuda"), # 将输入转换为张量并移到GPU
max_new_tokens = 64, # 限制输出长度(可以根据需要增加)
# Gemma-3推荐的生成参数
temperature = 1.0, # 控制输出的随机性
top_p = 0.95, # 核采样参数
top_k = 64, # top-k采样参数
# 实时输出流
streamer = TextStreamer(tokenizer, skip_prompt = True), # 跳过输入提示,只显示生成内容
)步骤11: 保存训练后的模型
保存模型
# 保存LoRA适配器(推荐方式)
# 这种方式只保存训练过程中新增的LoRA权重,文件很小
print("正在保存LoRA适配器...")
model.save_pretrained("gemma-3") # 保存模型(包含LoRA权重)
tokenizer.save_pretrained("gemma-3") # 保存分词器
print("✓ LoRA适配器和分词器已保存到 'gemma-3' 目录")
print("保存内容:")
print("- adapter_config.json: LoRA配置文件")
print("- adapter_model.safetensors: LoRA权重文件")
print("- tokenizer相关文件")
print("\n使用方法:")
print("1. 先加载原始Gemma3-4B模型")
print("2. 再加载这个LoRA适配器")
print("3. 即可获得微调后的模型")# 可选:保存完整的微调模型
# 将LoRA权重合并到原模型中,生成一个完整的模型文件
if False: # 设置为True以执行保存
print("正在保存完整的微调模型...")
model.save_pretrained_merged("gemma-3-finetune", tokenizer)
print("✓ 完整模型已保存到 'gemma-3-finetune' 目录")
print("注意:完整模型文件很大(几GB),但使用时不需要原始模型")# 可选:保存为GGUF格式
# GGUF格式支持量化,文件更小,推理速度更快
if False: # 设置为True以执行保存
print("正在保存GGUF格式模型...")
model.save_pretrained_gguf(
"gemma-3-finetune",
quantization_type = "Q8_0", # 量化类型:目前支持Q8_0, BF16, F16
)
print("✓ GGUF格式模型已保存")
print("特点:")
print("- 文件更小(通过量化压缩)")
print("- 推理速度更快")
print("- 适合部署到边缘设备")
print("- 可以用llama.cpp等工具加载")Swanlab
++SwanLab++ 是一个开源的模型训练记录工具,面向 AI 研究者,提供了训练可视化、自动日志记录、超参数记录、实验对比、多人协同等功能。在
SwanLab上,研究者能基于直观的可视化图表发现训练问题,对比多个实验找到研究灵感,并通过在线链接的分享与基于组织的多人协同训练,打破团队沟通的壁垒。
为什么要记录训练?
相较于软件开发,模型训练更像一个实验科学。一个品质优秀的模型背后,往往是成千上万次实验。研究者需要不断尝试、记录、对比,积累经验,才能找到最佳的模型结构、超参数与数据配比。在这之中,如何高效进行记录与对比,对于研究效率的提升至关重要。
在哪里用?
建议先在 ++SwanLab 官网++ 注册账号,然后在GRPO训练初始化阶段选择
from trl import GRPOConfig, GRPOTrainer
training_args = GRPOConfig(
# 优化器参数
learning_rate = 5e-6, # 学习率:GRPO通常使用较小的学习率
adam_beta1 = 0.9, # Adam优化器的beta1参数
adam_beta2 = 0.99, # Adam优化器的beta2参数
weight_decay = 0.1, # 权重衰减,防止过拟合
optim = "adamw_torch_fused", # 使用融合的AdamW优化器,更高效
# 学习率调度
warmup_ratio = 0.1, # 学习率预热比例
lr_scheduler_type = "cosine", # 余弦学习率调度
# 训练批次设置
per_device_train_batch_size = 1, # 每个设备的批次大小
gradient_accumulation_steps = 1, # 梯度累积步数(可以增加到4获得更平滑的训练)
num_generations = 4, # 每个提示生成的候选数量(显存不足时可减少)
# 序列长度控制
max_prompt_length = max_prompt_length, # 提示的最大长度
max_completion_length = max_seq_length - max_prompt_length, # 完成文本的最大长度
# 训练控制
max_steps = 50, # 最大训练步数(演示用,实际训练建议更多)
save_steps = 50, # 保存模型的步数间隔
max_grad_norm = 0.1, # 梯度裁剪阈值
# 日志和监控
logging_steps = 1, # 日志记录间隔
report_to = "swanlab", # 这里改成swanlab
output_dir = "outputs", # 输出目录
)本试验的试验记录
GRPO阶段
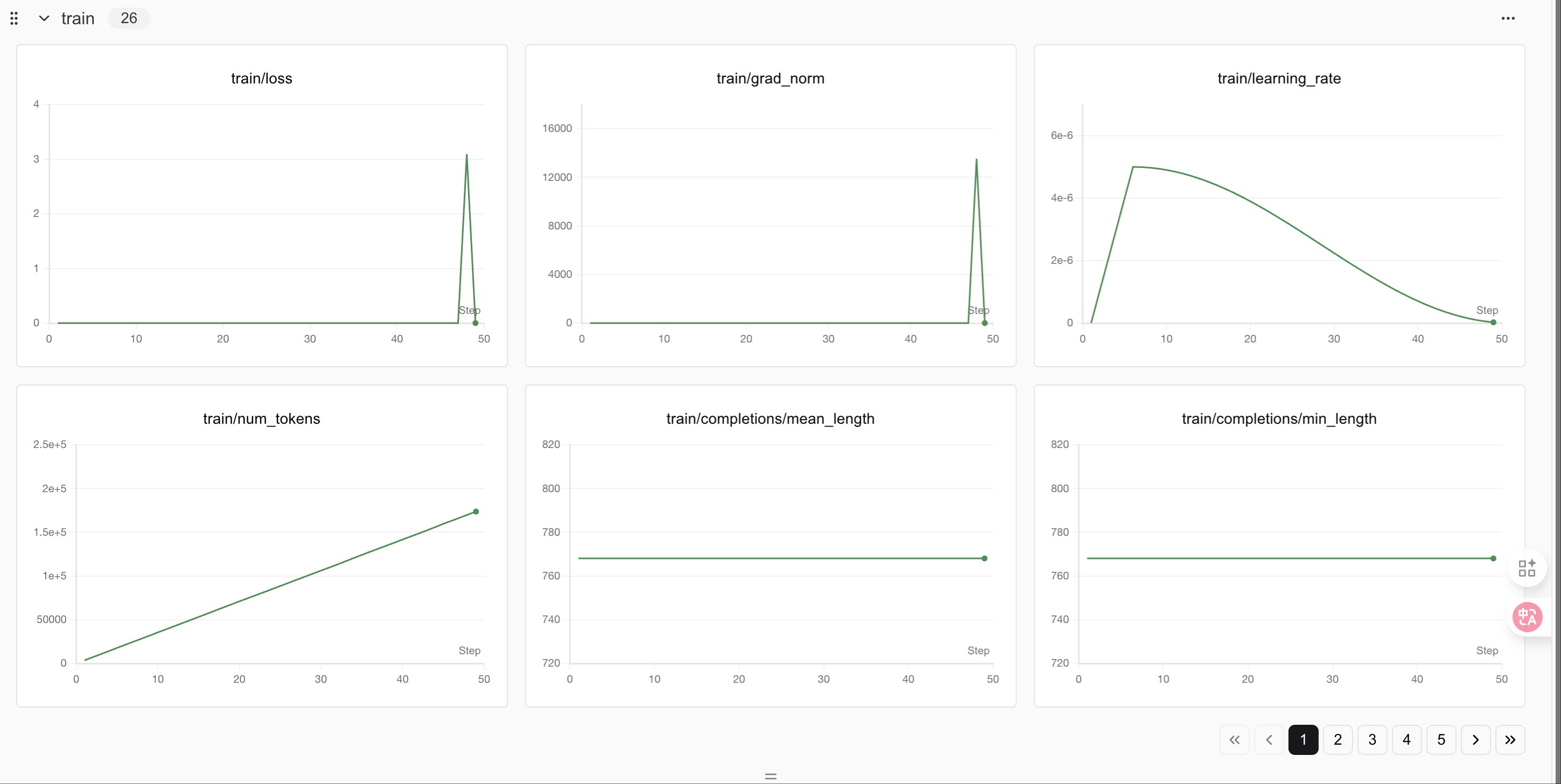 400个step之后loss会有明显变化
400个step之后loss会有明显变化
教程总结
🎉 恭喜!你已经成功完成了Gemma3-4B的GRPO微调教程。
本教程涵盖的核心概念:
- GRPO微调: 使用奖励函数指导模型学习特定输出格式
- LoRA技术: 高效的参数微调方法,节省显存和时间
- 奖励函数设计: 多层次评估体系,从格式到内容的全面评价
- 结构化输出: 训练模型按照特定格式输出推理过程和答案
- SwanLab监控: 实时跟踪训练进度和指标变化
学到的技能:
- ✅ 设置GRPO训练环境
- ✅ 设计多维度奖励函数
- ✅ 配置LoRA参数进行高效微调
- ✅ 处理数学推理数据集
- ✅ 监控和分析训练过程
- ✅ 保存和部署微调模型
进一步探索:
- 调整奖励函数: 设计更复杂的评估机制
- 扩展数据集: 使用更大或不同类型的数据集
- 优化参数: 尝试不同的LoRA配置和训练参数
- 模型评估: 在测试集上系统评估模型性能
- 应用部署: 将模型集成到实际应用中
注意事项:
- 本教程使用了较少的训练步数作为演示,实际应用中建议使用更多步数
- 可以根据显存情况调整批次大小和生成数量
- SwanLab提供了丰富的可视化功能,建议深入探索
感谢你的学习!如果有任何问题,欢迎查看SwanLab的实验记录或重新运行代码。
总结
Congratulations!看到了这,你已经初步实现了一个简单的RL实战,掌握了使用 Unsloth 对 Gemma3 这类大模型进行 GRPO 微调的具体操作步骤,更能体会到 Unsloth 在大幅提升训练速度、显著降低显存占用方面的强大优势,从而使在有限资源下进行复杂强化学习实验成为可能!如果支持我们的工作希望得到你的star!!这是我们持续更新的最大动力!!!