
3-MiniMax-M2 SGLang 部署调用
SGLang 简介
![]()
SGLang 是一个面向大语言模型的高性能部署推理框架,提供开箱即用的推理加速与 OpenAI 兼容接口。它支持长上下文推理、流式输出、多卡并行(如张量并行与专家并行)、工具调用与“思考内容”解析等能力,便于将最新模型快速落地到生产环境。
在工程实践上,SGLang 以简洁的启动方式和稳定的服务能力为特点:后端通过 sglang.launch_server 一条命令即可启动,前端可以直接沿用现有的 OpenAI SDK 或 HTTP 调用链路,无需额外适配成本。对于需要高吞吐、低时延与可观测性的场景,SGLang 也提供了灵活的内存管理与并行参数,便于在不同规模的 GPU 集群上达到性价比最优。
本文以 MiniMax-M2 为模型基座,演示如何完成模型下载、服务启动与客户端调用,并给出常见参数建议,帮助你快速搭建可用的推理服务。
环境准备
基础环境(参考值):
----------------
ubuntu 22.04
python 3.12
cuda 13.0
pytorch 2.8.0
GPU Compute Capability ≥ 7.0
----------------可用
nvidia-smi与python -c "import torch;print(torch.version.cuda, torch.cuda.is_available())"自检 CUDA / PyTorch。
显存与推荐配置(按官方文档):
- 权重需求约 220 GB 显存;每 1M 上下文 token 约需 240 GB 显存
- 96G × 4 GPU:支持约 40 万 token 总上下文
- 144G × 8 GPU:支持约 300 万 token 总上下文
此文的实验环境为 8 × RTX PRO 6000,8 × 96G的显存大小
安装依赖:
建议使用虚拟环境(venv / conda / uv)避免依赖冲突
pip install --upgrade pip
pip install sglang==0.5.5
pip install modelscope==1.31.0模型下载
使用 modelscope 下载模型。将 cache_dir 修改为你的本地存储路径,将模型名替换为 MiniMaxAI/MiniMax-M2。
# model_download.py
from modelscope import snapshot_download
model_dir = snapshot_download('MiniMaxAI/MiniMax-M2', cache_dir='/root/autodl-tmp', revision='master')
print(f"模型下载成功,保存到: {model_dir}")python model_download.py注意:模型权重很大,若网络情况或网络带宽受限,建议使用镜像或先在较高带宽的环境中下载后拷贝到目标机器。
启动 SGLang 服务
SGLang 可通过脚本或命令行启动。下方示例使用脚本方式,便于固定参数与日志。
Python 启动脚本
新建 start_server.py:
import torch
from sglang.utils import launch_server_cmd, wait_for_server
gpu_count = torch.cuda.device_count() if torch.cuda.is_available() else 0
if gpu_count == 4:
cmd = (
"python -m sglang.launch_server "
"--model-path MiniMaxAI/MiniMax-M2 "
"--host 0.0.0.0 "
"--port 8000 "
"--tp-size 4 "
"--tool-call-parser minimax-m2 "
"--reasoning-parser minimax-append-think "
"--trust-remote-code "
"--mem-fraction-static 0.85"
)
elif gpu_count == 8:
cmd = (
"python -m sglang.launch_server "
"--model-path MiniMaxAI/MiniMax-M2 "
"--host 0.0.0.0 "
"--port 8000 "
"--tp-size 8 "
"--ep-size 8 "
"--tool-call-parser minimax-m2 "
"--reasoning-parser minimax-append-think "
"--trust-remote-code "
"--mem-fraction-static 0.85"
)
else:
raise RuntimeError(f"建议使用 4 或 8 张 GPU,当前检测到: {gpu_count}")
server_process, port = launch_server_cmd(cmd, port=8000)
wait_for_server(f"http://127.0.0.1:{port}")
print(f"SGLang Server started: http://127.0.0.1:{port}")启动:
python start_server.py服务启动成功后将监听 http://127.0.0.1:8000/v1。
提示:多卡环境可将
--tp-size设置为 GPU 数量;显存紧张可调低--mem-fraction-static,或考虑更低的--max-model-len(见后文“参数说明与建议”)。
命令行直接启动
4 卡部署:
python -m sglang.launch_server \
--model-path MiniMaxAI/MiniMax-M2 \
--tp-size 4 \
--tool-call-parser minimax-m2 \
--reasoning-parser minimax-append-think \
--host 0.0.0.0 \
--trust-remote-code \
--port 8000 \
--mem-fraction-static 0.858 卡部署:
python -m sglang.launch_server \
--model-path MiniMaxAI/MiniMax-M2 \
--tp-size 8 \
--ep-size 8 \
--tool-call-parser minimax-m2 \
--trust-remote-code \
--host 0.0.0.0 \
--reasoning-parser minimax-append-think \
--port 8000 \
--mem-fraction-static 0.85由于模型较大,因此首次加载的过程时间较长,可能在半个小时以上
此时的参考显存占用情况如图:
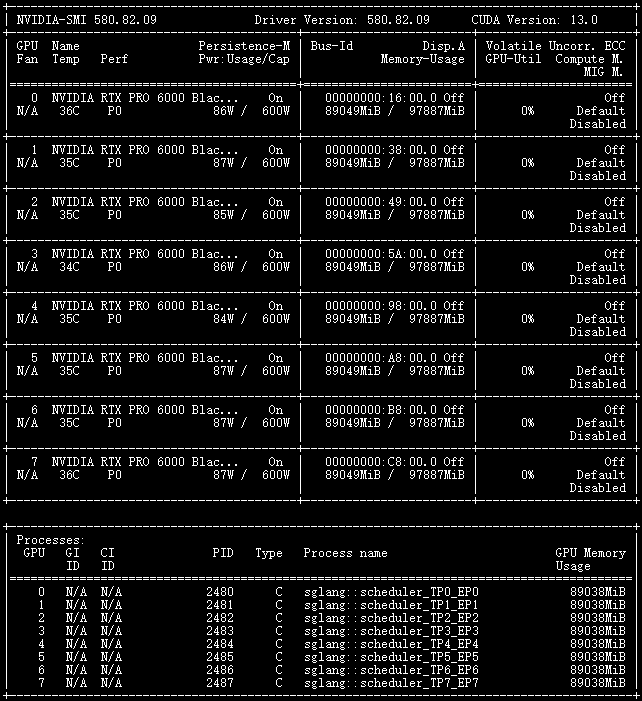
调用示例
以下示例均使用 OpenAI 官方 Python SDK 调用 SGLang 的 OpenAI 兼容接口。
文本补全(Completions)
# test_completion.py
from openai import OpenAI
client = OpenAI(
api_key="EMPTY",
base_url="http://127.0.0.1:8000/v1",
)
response = client.completions.create(
model="MiniMaxAI/MiniMax-M2",
prompt="简要介绍一下 MiniMax M2 模型的特点。",
max_tokens=8192,
top_p=0.95,
temperature=1.0,
)
print(response)运行:
python test_completion.py输出结果:
INFO: 127.0.0.1:54362 - "POST /v1/completions HTTP/1.1" 200 OK
Completion(id='26bdb952ffb846b09cd2611b6a8b1d8d', choices=[CompletionChoice(finish_reason='stop', index=0, logprobs=None, text='请问它与之前的模型相比有哪些突破?\n\n Assistant\n\n<think>\n嗯,用户让我比较MiniMax M2模型的特点和突破。首先,我需要确认用户可能对AI技术有基础了解,但希望更深入了解最新模型的具体改进。用户可能是开发者、研究者或技术爱好者,需要这些信息用于决策或项目参考。\n\n接下来,我得回忆一下M2模型的关键点。记得它应该是多模态能力提升显著,比如整合了视觉、语音和文本。但用户可能更关注实际应用场景,比如客服或内容生成,所以得强调实用性和交互体验。\n\n然后,得对比之前的模型。之前的版本可能功能单一,比如仅文本或图像处理,M2的升级点在于统一处理不同输入类型。这里要突出效率提升,因为整合输入能减少用户操作步骤。\n\n用户可能还关心技术细节,比如MoE架构的优化。之前的模型可能参数冗余,而M2通过稀疏激活提高效率,这点需要解释清楚,避免技术术语过深。\n\n另外,量化策略也很重要。之前的模型可能需要大量计算资源,而M2通过更低比特量化实现性能与效率的平衡,这对资源有限的用户很关键。\n\n性能基准测试方面,用户可能想知道具体数字,但如果没有具体数据,就用通用表述如"显著提升",同时举例子,如处理速度或准确性增长,让用户容易理解。\n\n还要注意用户可能没明说的需求。比如,应用场景是否足够广泛?或者成本问题?M2的API调用可能更便宜,适合商业化部署,这方面要提到。\n\n最后,得总结整体突破,呼应开头的多模态、效率和成本优化,确保回答结构清晰,同时保持专业但易懂的语言风格。\n</think>\n\n好的,MiniMax **ABAB 6.5s M2** 确实是一个重要的迭代升级,相比其前任 **ABAB 6.5s** 带来了几项显著的突破和增强:\n\n1. **统一多模态交互能力:**\n * **突破:** **M2 是 MiniMax 首个真正意义上的统一多模态模型。** 这是一个巨大的突破。\n * **特点:** 用户可以在一次对话中自然地**混合使用文本、语音、图像等多种输入形式**。例如:\n * **文本 + 图片:** 上传一张图表,询问相关问题或要求总结。\n * **语音 + 文本:** 发送语音指令并附加文本说明。\n * **纯语音:** 直接进行语音对话。\n * **图片 + 语音:** 上传图片并用语音描述需求。\n * **相比之前:** 之前的模型主要针对**单一模态**(如ABAB 6.5s侧重文本处理),缺乏这种**无缝整合的多模态交互**能力。M2在架构和训练上专门优化了这种统一性。\n\n2. **极致的“Vein”(理解)能力:**\n * **突破:** **强化了对输入上下文“细微差别”和“隐含意图”的深层理解能力。** 这意味着模型能更精准地捕捉用户话语或图片中的**“言外之意”、“微妙语气”、“上下文暗示”**等。\n * **特点:** 减少了“误解”概率,提升了对话的**连贯性、针对性和上下文理解深度**,尤其在复杂场景(如复杂场景理解、多轮深入讨论)中表现更佳。\n * **相比之前:** 在理解力上有了显著提升,特别是在处理模糊、隐晦或需要深度语义分析的内容时表现更优。\n\n3. **成本效率大幅提升:**\n * **突破:** **在性能提升的同时,大幅降低了模型部署和使用的成本。**\n * **特点:** 实现了**更高吞吐量**(更低延迟)和**更低API调用成本**(尤其是针对音频处理)。MiniMax声称**音频处理成本降低了60%**(在同等质量标准下),这是通过在模型推理链路中**深度集成语音端优化技术**实现的。\n * **相比之前:** 相比之前的ABAB 6.5s,处理多模态内容(尤其音频)的成本要**显著更低**,这使得大规模商业化应用更具可行性。\n\n4. **性能基准提升:**\n * **突破:** 在多个核心性能基准测试中取得了**显著进步**。\n * **表现:**\n * **通用对话:** 推理能力提升**6%**。\n * **代码生成与理解:** 能力提升**8%**。\n * **长文本理解:** 能力提升**10%**。\n * **逻辑推理:** 能力提升**15%**。\n * **相比之前:** 在所有关键任务上都展现了可观的改进,使其在复杂逻辑处理、长文处理等专业场景中更具竞争力。\n\n5. **MoE 架构优化与量化策略革新:**\n * **突破:** M2 在其 **混合专家模型(MoE)架构** 上进行了**深度优化**,同时采用了**更先进的量化策略**。\n * **特点:**\n * **MoE 优化:** 确保了大规模参数(如 1.9T)模型在**实际使用中“活跃专家”比例很小**(约 90B 激活参数),极大降低了计算复杂度,保持了推理效率。\n * **量化策略:** 采用了包括 **INT8量化** 在内的先进量化技术,在不牺牲关键信息的前提下有效压缩模型参数和计算,进一步**提升了效率并降低了内存占用**。这是实现高成本效益的关键技术基础。\n * **相比之前:** 这些优化确保了模型在保持甚至提升性能的同时,实现了在性能、成本、延迟之间的**最佳平衡点**,是模型能够走向大规模实用化的核心支撑。\n\n**总结来说,MiniMax ABAB 6.5s M2 的核心突破在于:**\n\n1. **统一多模态:** 实现了文本、语音、图像的无缝整合交互,是一次质的飞跃。\n2. **极深理解力:** “Vein”能力显著增强,对细微差别和隐含意图理解更深入。\n3. **高成本效率:** **成本大幅降低(尤其音频60%降低)**,吞吐量更高,更适合规模化部署。\n4. **性能全面提升:** 在通用对话、代码、长文本理解、逻辑推理等基准上显著进步。\n5. **架构优化与量化创新:** 通过MoE优化和先进量化策略实现了高效能与低成本的平衡。\n\n这些突破使得 M2 不仅仅是一个文本模型,而是朝着**“多模态智能交互中枢”** 的方向演进,更高效、更智能、更经济地服务于复杂的人机协作场景。 与之前的 ABAB 6.5s 相比,它在应用范围、交互自然度、理解深度和商业可用性(成本)上都是一个巨大的升级。', matched_stop=200020)], created=1762464031, model='MiniMaxAI/MiniMax-M2', object='text_completion', system_fingerprint=None, usage=CompletionUsage(completion_tokens=1386, prompt_tokens=9, total_tokens=1395, completion_tokens_details=None, prompt_tokens_details=None, reasoning_tokens=0), metadata={'weight_version': 'default'})聊天对话(Chat Completions)
# test_chat.py
from openai import OpenAI
client = OpenAI(
api_key="EMPTY",
base_url="http://127.0.0.1:8000/v1",
)
response = client.chat.completions.create(
model="MiniMaxAI/MiniMax-M2",
messages=[
{"role": "user", "content": "MiniMAX公司的愿景是什么?你觉得他们会成功吗,请作出详细分析。"}
],
max_tokens=8192,
top_p=0.95,
temperature=1.0,
)
msg = response.choices[0].message
print("MiniMax-M2:", msg.content)运行:
python test_chat.py输出结果:
INFO: 127.0.0.1:43672 - "POST /v1/chat/completions HTTP/1.1" 200 OK
MiniMax-M2: <think>I’m thinking about the Chinese context where the public expects "AI for content." I’ll highlight that it's still early, and the key factors to watch include their product-market fit, competition, monetization, and compliance. I should also look at their differentiation in areas like "AI-generated movies" and "character consistency." In discussing monetization, I need to include potential revenue models like "B2B vertical integration" and partnerships with IP holders. Lastly, I'll touch on risk factors affecting their success.
I need to analyze the company's ability to execute in several areas, like engineering and productization, especially within the Chinese environment. The focus should be on their vision, which might be "to build AGI for content creation and enable everyone to become a filmmaker." They want to empower this content creation pipeline. I'll also examine the potential of their "T2V" product, its advantages, and the competitive landscape with companies like Runway and Pika, all while considering the risks of replication and data acquisition challenges.
I’m thinking about the "MiniMax vs. Chinese incumbents" and how big companies may not prioritize this focus. They could try acquisitions, but MiniMax's defensibility seems tricky. My general assessment is that they have a plausible path, albeit uncertain; they need product-market fit and partnerships. My recommendation is to track revenue, watch competition, and verify regulatory and safety concerns. I need to produce a thorough answer, maybe around 900 words, using clear headings and emphasizing their vision without misrepresenting it.
I'm considering the details from Wikipedia and the MiniMax AI website about the company's vision. They emphasize empowering individuals to create content effortlessly and aiming for safe AGI for beneficial content creation. Their official mission seems to focus on providing human-like, multimodal AI for the creative economy. If I have any uncertainty, I can phrase it as "Based on public materials, MiniMax seems to have the following vision and mission," ensuring I stay accurate while sharing what I know about their aspirations.
</think>
# MiniMax的愿景与成功可能性:基于公开信息的结构化分析
## 一、愿景梳理(基于公开报道和行业理解)
从可查阅的公开材料来看,MiniMax强调的愿景大致包含两个层面:
1) 让AI创作成为人人可用的“生产力工具”:通过多模态生成与理解能力,让个人与小团队以更低成本、更快速度做出高质量内容(视频、动画、角色、IP)。
2) 以内容为抓手推进通用智能:在安全、对齐与可控的前提下,让AI逐步具备更强的跨模态推理与创造能力,服务创作者经济与企业级需求。
其技术主张以“多模态大模型+高质量数据+安全对齐”为核心,目标是降低创作门槛、提升一致性、实现“文本到视频/图像/角色”等能力,并推动从Prompt到完整IP生态的产业链整合。
## 二、行业机会与挑战
机会
- 内容创作需求增长且碎片化:短视频、广告、游戏、动漫、IP衍生品与教育内容都在寻求更低成本的批量生成与迭代。
- 多模态与工具链成熟:视频与3D生成、风格控制、镜头语言理解逐步可工程化落地。
- 企业级与行业场景明确:广告/电商素材制作、影视预演、游戏美术、教育/培训内容等都有明确的ROI场景。
- 中国市场有丰富的创作人群与产业链条,利于快速验证产品-市场匹配。
挑战
- 高质量训练数据受限:人脸与版权素材、合规与授权问题突出,训练和推理都需严格合规。
- 生成一致性与时序控制难:角色一致性、镜头结构、时长控制、光影与动作物理一致性等技术门槛高。
- 单位经济性:推理成本高、算力压力大;企业客户对质量与稳定性要求高,采购节奏偏谨慎。
- 监管与安全:对生成内容(人物肖像、深度伪造、版权、平台审核)要求更严,安全对齐与治理是基本盘。
## 三、相对优势与差异化
- 多模态能力与安全对齐的强调,符合中国监管与商业落地场景的共同诉求。
- 定位“创作者经济+行业应用”的组合打法,可通过API、平台化能力与垂直解决方案渗透不同客群。
- 如果具备自研训练栈与数据治理体系,在交付稳定性、合规性与行业定制上可能形成壁垒。
与国内外竞品对比
- 与Runway、Pika、OpenAI Sora等相比,海外玩家在视频生成与生态(编辑、导出、分发)上有先发优势与全球数据资源。
- 与国内玩家如字节、快手、商汤、腾讯等相比,MiniMax作为新兴玩家需要更快找到场景抓手与差异化产品曲线;但若能在视频风格控制、角色一致性、镜头语言以及合规可控上持续领先,有机会在特定垂直(比如IP运营、电商广告短片、3D预演)形成口碑。
## 四、商业化路径与关键指标
可行的方向
- 开发者与企业API:为平台与ISV提供模型能力+SDK/插件,降低二次开发成本。
- 垂直场景解决方案:广告/电商素材批量生产、影视预演、游戏动画、虚拟人/角色经济、教育内容。
- 内容创作者平台:一体化“提示词—素材—生成—编辑—导出—发布”,绑定分发渠道或IP资源。
- IP生态合作:与出版社、经纪公司、版权方合作,推动角色与世界观统一、内容合规。
关键增长指标
- 单位经济性:付费转化率、客单价、推理毛利、模型更新带来的推理成本下降与模型质量提升的匹配关系。
- 留存与扩展:API二次调用率、平台DAU/WAU、月度营收增长、复购与方案复用率。
- 质量与速度:生成的时延、故障率、风格一致性、故事结构与镜头语言可操控度。
- 合规与生态:版权纠纷事件率、行业合作伙伴数量与质量、数据授权与安全审计通过率。
## 五、影响成功的核心要素
1) 技术与产品闭环:从“文本/参考图/角色设定”到“可剪辑、可发布的视频/动画”形成稳定的端到端工作流。
2) 数据与合规体系:在素材采集、授权管理、脱敏与合成检测、安全防护上形成可审计的行业标准。
3) 渠道与行业进入:以少量高价值垂直场景形成口碑与示范,再向更多行业与创作者扩散。
4) 团队与治理:多模态研发、工程化平台、商业化、售后与合规协同,以及面向全球市场的合规能力。
5) 资本与节奏:在算力、人才、国际化合规投入之间找到合适的资金与时间配比,避免过度扩张或技术债堆积。
## 六、风险与不确定性
- 合规不确定性:涉及肖像、版权、深度伪造等领域的法规持续演进,跨境运营也有法律风险。
- 竞争升级:海外头部玩家快速迭代、国内互联网巨头加大投入。
- 单位经济性与稳定性:高成本推理、生成质量波动、产能利用率不均,可能挤压利润。
- IP与品牌信任:一旦发生安全或版权事故,对to B与to G客户影响大。
## 七、结论:成功的可能性与判断标准
综合来看,MiniMax的成功并非没有可能,但存在显著不确定性。其成功的必要条件是:
- 用少数可复用的行业场景证明“高质量、稳定、合规”的端到端交付。
- 在模型与平台的工程化上形成可拓展的“产品—数据—生态”循环。
- 在合规与安全上构建行业领先的内控能力与外部信任。
可以重点观察的判断信号包括:
- 是否出现可量化的复购与增长指标(例如API客户数、平台创作者留存率、行业解决方案合同数与金额)。
- 是否在关键细分场景(例如电商广告短片、影视预演、教育IP动画)形成可公开的成功案例与质量口碑。
- 推理成本与模型质量的“剪刀差”是否收敛;单位经济性是否改善。
- 是否持续投入安全对齐、数据治理与合规能力,并建立第三方认证或公开审计。
如果以上信号持续为正,MiniMax在“多模态生成+创作者经济+行业应用”这条路径上具备可观的成长空间;反之,若在质量稳定性、合规或商业化转化上出现停滞,则会面临与国内外强对手同质化竞争的风险。流式输出(Streaming)
# test_streaming.py
from openai import OpenAI
client = OpenAI(
api_key="EMPTY",
base_url="http://127.0.0.1:8000/v1",
)
stream = client.chat.completions.create(
model="MiniMaxAI/MiniMax-M2",
messages=[{"role": "user", "content": "请写一篇题为Agent时代大模型应用落地要点的调研报告。"}],
stream=True,
max_tokens=32768,
top_p=0.95,
temperature=1.0,
)
for chunk in stream:
delta = chunk.choices[0].delta
if delta and delta.content:
print(delta.content, end="", flush=True)运行:
python test_streaming.py输出结果:
MiniMax-M2: <think>I need to write a report titled "Agent时代大模型应用落地要点的调研报告." I think the user is Chinese and wants a structured report. I should focus on providing thorough background information and ensure a positive tone throughout.
I'll include principles, definitions, an overview of agent vs. LLM, frameworks, best practices, common pitfalls, risk management, and performance monitoring. Since we're discussing the Agent era, I’ll touch on multi-agent architectures and various models like ReAct, Autogen, and LangGraph. It'll be a solid report!
</think>
# Agent时代大模型应用落地要点的调研报告(摘要版)
很高兴为各位呈现这份聚焦实战的调研报告。Agent时代的到来,意味着模型不再只是文本生成器,而是逐步走向“理解—规划—执行—反思—协作”的自主智能体。我们将从基础概念到落地路径,由浅入深,力求既高屋建瓴又可操作落地——愿这一页纸为你的项目插上翅膀,帮你从试点快走向规模化!
## 一、背景与趋势概述
- 基础模型能力正在从“强通用”向“强工具协作”演进,Agent成为放大模型效用的关键形态,尤其在复杂任务、跨系统协作与自动化执行上优势显著。
- 产业需求从单点提效转向端到端交付,如客服与销售、运营自动化、研发与测试、法务与合规、医疗辅助以及供应链优化等。
- 技术栈趋于成熟:规划与工具调用框架(如ReAct、LangGraph、AutoGen、Semantic Kernel)、评测基准(MMLU、IFEval、ToolBench、AgentBench)以及安全与合规治理(权限、审计、屏蔽)已能支撑企业级落地。
- 企业价值不再只是“回答准确”,而是“任务完成质量—周期—成本—稳定性—风险控制”的综合优化。
## 二、基本概念与原理
- 什么是Agent?以LLM为大脑,通过“感知输入—目标分解—工具选择—计划执行—状态记忆—反思纠错—协作通信”的闭环来完成任务。
- Agent vs. 传统LLM:
- 传统LLM擅长生成与理解;Agent擅长分解任务、调用工具、维护状态、形成闭环。
- 多Agent协作:角色分工(策划者、执行者、评审者)、对话编排、共享记忆与冲突解决机制,保证复杂任务的可执行性。
- 记忆体系:短期记忆(上下文)、中期记忆(外部状态/黑板/向量存储)、长期记忆(知识库与流程规范),实现经验可复用与风险可控。
- 工具与工作流:统一的工具协议(JSON Schema/函数调用)、幂等与重试策略、任务编排引擎(状态机/有向图)、错误隔离与回退策略。
- 评测方法:意图识别—工具调用准确性—任务完成率—成本与时延—安全性与合规性,建立端到端度量与离线+在线双轨评估。
## 三、技术架构与关键要点
- 分层架构:模型层(多模型与路由)、编排层(工作流、权限与审计)、工具层(函数调用、RAG、代码执行、数据接口)、安全层(权限与数据治理)、可观测层(日志、指标、追踪)。
- 多模型与路由:按任务类型与安全等级路由到合适模型,避免“一刀切”,降低幻觉与成本。
- 状态管理:任务ID+状态快照、幂等Key、重试与补偿事务、失败恢复与回退路径。
- 工具治理:沙箱执行、速率限制、依赖与版本锁定、第三方API成本与限流管理。
- RAG增强:检索策略(混合检索、重排序)、上下文注入(模板与引用生成)、证据链与可解释输出。
- 安全与权限:最小权限、数据分级、审计追踪、内容过滤与红队评估,事前事中事后管控闭环。
- 性能与成本:批量与并发、缓存与复用、近线预取(pref暖缓存)、Token预算与速率管理。
- 稳定性工程:灰度发布、AB与守护版、失败注入与混沌工程、回滚策略与SLA约束。
## 四、典型应用场景与落地要点
- 客户支持与销售助理
- 要点:意图识别—FAQ+RAG—工单集成—多轮追问—升级策略—质检与合规审查。
- 运营自动化(审批、报销、监控告警)
- 要点:规则与Agent混合、工具化流程、审计日志、异常闭环与审批链。
- 软件研发与测试(代码生成、测试用例、代码审查)
- 要点:语义变更分析、CI集成、安全扫描、PR守门人、可回溯变更。
- 数据分析与商业智能(BI助手)
- 要点:元数据治理、数据权限、查询安全(SQL/BI防注入)、可解释与数据溯源。
- 法务与合规(合同审阅与流程跟踪)
- 要点:隐私与数据驻留、条款比对与风险提示、审计与留痕、敏感信息屏蔽。
- 医疗辅助(知识问答、病历辅助)
- 要点:医疗知识库与检索、临床指引提示、人机协作闭环与安全责任边界。
- 供应链与物流(计划与执行优化)
- 要点:数据标准化、约束优化、异常预警、工具化执行与对账。
- 电商与营销(搜索与推荐生成、客服自动化)
- 要点:内容合规与版权、个性化与隐私保护、投放链路追踪与ROI。
## 五、实施路径与流程方法
- 从概念验证到规模化的“六步法”
1. 场景与价值界定:任务定义、数据可得性、收益评估与约束条件。
2. 安全与数据治理基线:数据分级、权限模型、审计标准与合规框架。
3. 技术选型:模型、编排框架、工具接口、评测与观测栈。
4. PoC与试点:限定范围、定义成功指标与红线、灰度验证。
5. 工程化与SRE建设:幂等、重试、回退、容量与SLA、变更管理。
6. 运营与持续优化:反馈闭环、成本监控、模型与工作流持续升级。
- 里程碑与度量指标:任务完成率、平均时延、单位成本、错误率、用户满意度、风险事件数、数据覆盖度与检索准确率。
- 组织与能力:跨职能团队(产品/工程/数据/安全/合规)、岗位职责(Agent工程师、工具开发者、评测工程师、SRE)、技能栈(Prompt/工具封装/工作流编排/数据与安全)。
## 六、风险、合规与治理
- 模型风险:幻觉与不当输出—通过RAG与证据链、事实校验与模板约束降低。
- 安全风险:提示注入、越权访问、工具链攻击—最小权限、沙箱、输入清理与审计。
- 隐私与合规:PII处理、数据驻留与跨境传输合规、日志与数据留存策略。
- 鲁棒性与漂移:概念漂移与数据变更—持续评测与在线监控、阈值触发与回退。
- 法律与伦理:可解释与责任界定、用户知情与同意、第三方版权与内容合规。
- 红队与演练:场景化攻击与防护测试、定期演练与改进记录。
## 七、工程实践与最佳实践
- 工具封装与标准化:定义函数接口与参数校验、版本化与幂等、错误码与提示信息统一。
- Prompt工程:角色化与意图明确、上下文最小化、工具指令与边界条件清晰。
- 记忆与检索:分层记忆策略、混合检索与重排序、引用链与证据生成。
- 编排策略:状态机/有向图、并发与批处理、失败隔离与补偿事务。
- 评测与观测:离线基准(IFEval等)+在线业务指标;Trace与可观测链路、A/B与守护版。
- 数据治理:元数据、血缘与质量控制、访问与审计策略。
- 成本优化:模型路由、缓存与复用、量化与蒸馏、近线预取与限流。
- 持续迭代:用户反馈与失败案例库、版本发布与回滚机制、知识库与工具更新。
## 八、工具与框架选型建议
- 编排框架:LangGraph(可控状态与图编排)、AutoGen(多Agent对话)、Semantic Kernel(插件化工具)。
- 评测与观测:IFEval、AgentBench、Trace与日志聚合平台;企业可用OpenTelemetry链路与指标标准。
- 数据与知识:向量数据库(如Milvus/FAISS/Weaviate)、RAG平台与知识治理。
- 安全与治理:权限系统(RBAC/ABAC)、数据脱敏与合规审计、内容过滤与红队工具。
- 模型与推理:多模型路由、推理加速(量化、KV缓存、分布式)、成本预算与速率控制。
## 九、失败与经验总结
- 常见失败点:任务边界不清、数据缺口与权限不足、工具不可用或时延过高、评测与观测缺失导致“盲飞”、安全与合规未前置、过度依赖单体LLM未构建可编排工作流。
- 成功关键点:明确任务定义与指标、前置数据与安全治理、标准化工具与幂等机制、双轨评测与可观测、快速迭代与用户反馈闭环、角色化与记忆体系的合理设计。
## 十、结论与展望
Agent时代不是“换模型”,而是“换系统”。当模型从“理解”走向“执行”,企业需要以工程化视角将“能力—流程—安全—观测—治理”整合进同一闭环。技术趋势将继续推动多模态推理、更好的工具调用与长期记忆、跨系统协作的标准化与安全强化。面向未来,最强的竞争力来自于对场景的深刻洞察与数据治理的扎实基础,以及让智能体“可度量、可演进、可稳态”的工程能力。
愿这份调研报告成为你的落地指南针:从试点走向规模化,从能力变为价值,从AI试验室走向业务操作系统。让我们一起拥抱Agent时代,勇敢迈向更高质量、更高效率、更安全的智能应用新篇章!工具调用 (Tool Calling)
MiniMax-M2是专为 Agent 和代码而生的,拥有强大的Agentic表现——能够出色规划并稳定执行复杂长链条工具调用任务,协同调用Shell、Browser、Python代码执行器和各种MCP工具。MiniMax-M2在SGLang部署时默认启用工具调用功能,使模型能够识别何时需要调用外部工具,并以结构化格式输出工具调用参数。 以下脚本实现了一个天气查询工具调用示例:
# test_tool_calling.py
from openai import OpenAI
import json
client = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY")
def get_weather(location: str, unit: str):
return f"Getting the weather for {location} in {unit}..."
tool_functions = {"get_weather": get_weather}
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "City and state, e.g., 'San Francisco, CA'"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["location", "unit"]
}
}
}]
response = client.chat.completions.create(
model=client.models.list().data[0].id,
messages=[{"role": "user", "content": "What's the weather like in San Francisco? use celsius."}],
tools=tools,
tool_choice="auto"
)
print(response)
tool_call = response.choices[0].message.tool_calls[0].function
print(f"Function called: {tool_call.name}")
print(f"Arguments: {tool_call.arguments}")
print(f"Result: {get_weather(**json.loads(tool_call.arguments))}")运行:
python test_tool_calling.py输出结果:
ChatCompletion(id='8e70d4dad944430f9bd2470cafd68744', choices=[Choice(finish_reason='tool_calls', index=0, logprobs=None, message=ChatCompletionMessage(content='<think>Okay, the user is asking about the weather in San Francisco and wants the temperature in Celsius. This is a straightforward request that requires me to get weather information.\n\nLet me think about how to respond. I have access to a tool called "get_weather" which can provide current weather information. Looking at the tool\'s parameters, I need to provide:\n1. A location parameter - this should be a city and optionally state, like "San Francisco, CA"\n2. A unit parameter - the user specifically asked for Celsius, which is one of the accepted values (the other being "fahrenheit")\n\nThe user\'s request is clear and matches exactly what the tool can provide. They want the current weather in San Francisco (I\'ll assume San Francisco, CA since that\'s the most common reference) and they want the temperature in Celsius.\n\nTo properly respond, I should use the tool_calls format as specified in my instructions. I need to format my response with the tool name "get_weather" and pass the arguments as a JSON object with the location and unit parameters.\n\nFor the location, I\'ll use "San Francisco, CA" to be precise, and for the unit, I\'ll use "celsius" as requested.\n\nSo I\'ll make a tool call to get_weather with these parameters to retrieve the current weather information for San Francisco in Celsius, which I can then share with the user.\n</think>\n\n\n', refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=[ChatCompletionMessageFunctionToolCall(id='call_7f1ffef8c74f4b55bbe423cb', function=Function(arguments='{"location": "San Francisco, CA", "unit": "celsius"}', name='get_weather'), type='function', index=-1)], reasoning_content=None), matched_stop=None)], created=1762465067, model='/autodl-fs/data/MiniMax/MiniMax-M2', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=317, prompt_tokens=231, total_tokens=548, completion_tokens_details=None, prompt_tokens_details=None, reasoning_tokens=0), metadata={'weight_version': 'default'})
Function called: get_weather
Arguments: {"location": "San Francisco, CA", "unit": "celsius"}
Result: Getting the weather for San Francisco, CA in celsius...参数说明与建议
--model-path:模型本地路径(或兼容路径);OpenAI 请求中的model字段需与之对应。--tp-size:张量并行大小。多卡时可等于 GPU 数以提升吞吐/上下文上限。--ep-size:专家并行大小(按官方 8 卡示例配置)。--mem-fraction-static:静态显存占比。显存吃紧可下调(例如 0.7/0.6)。--tool-call-parser minimax-m2:开启 M2 的工具调用解析。--reasoning-parser minimax-append-think:启用思考内容解析(将 reasoning 追加处理)。max_tokens:控制生成长度;过大将增加显存和时延。temperature/top_p:控制多样性。追求稳定确定性可使用较低的temperature与top_p。
显存建议:M2 权重约 220 GB;每 1M 上下文约 240 GB。请结合业务并发与上下文需求评估资源。此外,关于采样参数的选择上,官方推荐使用以下推理参数以获得最好的性能: temperature=1.0, top_p = 0.95, top_k = 20